Writing
Blog 02
LymeGPT, or How AI Saved My Life
How I used Langchain and GPT3.5 to heal my life-threatening Lyme Disease.
In my last post There and Back Again I related the harrowing tale of how just a few years ago my life and my body got completely wrecked by Lyme Disease, and how I made it back.
There were many factors that led to my eventual recovery, where today I can say I am nearly back to normal. One key factor was creating a customized version of Chatgpt that was "injected" with my growing stash of curated Lyme Disease knowledge. This included books, articles, podcast transcripts, and even reddit threads I had used to become a pseudo-expert on the disease and its treatment.
Why was this so important? Well, becoming an expert in Lyme Disease (or if you are lucky and well-funded, you have access to an expert) is a prerequisite for recovering from a complex or severe case of it. You WILL NOT casually recover from a severe case of Lyme Disease, by just taking some medication or supplements and hoping for the best. Your immune system will not "figure it out" on its own. You must be proactive, find out what works for you, and iterate relentlessly. If you are complacent, you will get worse. To complicate matters, and I don't want this post to turn into a rant, but lets just say the information landscape on Lyme Disease is "unreliable".
When Chatgpt came out in late 2022, I was still mostly bedridden and in dire need of treatment guidance. I was beyond excited to have access to this sci-fi level all-knowing AI. Lyme Disease was one of the first things I asked about, but I quickly found out it's knowledge had been borked. It was parrotting a lot of the misinformation that was in its training data, often refused to talk about details for "ethical reasons", and hallucinated constantly no matter what kind of prompt engineering I conjured. However, I could see its potential, it was amazing at language in general, it just needed to have its context steered to trusted information sources.
I discovered Langchain in its very early days via twitter. They had just done a hackathon where they showed off a crude RAG workflow and a few basic document loaders. I cloned this hackathon repo from their github and went to work setting up my own "LymeGPT". I used OpenAI's embedding model API to vectorize my Lyme Disease knowledge collection into ChromaDB. I then configured GPT3.5 to retrieve context from the ChromaDB vector database any time it was asked a medical question.
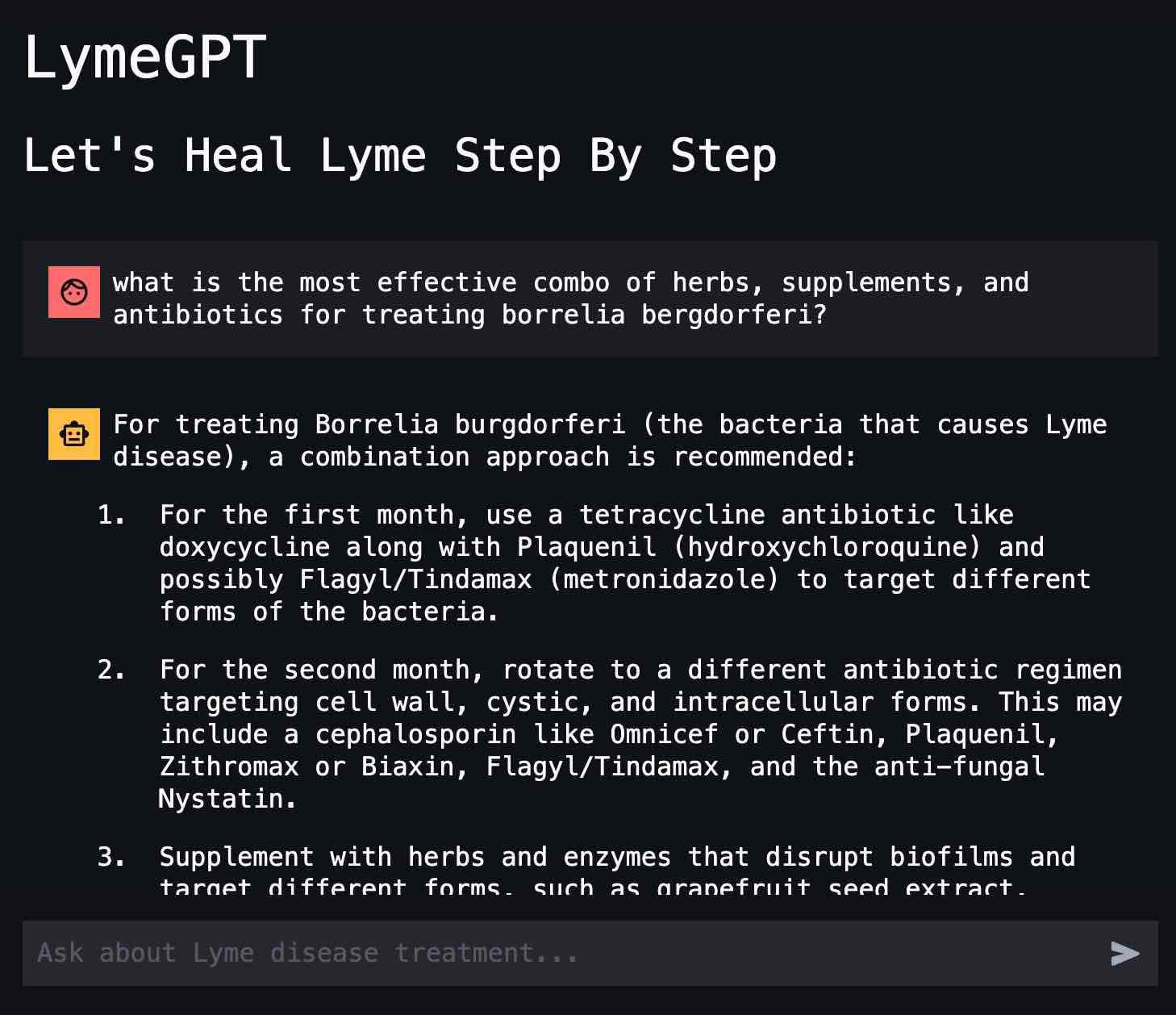
The result was pure magic. Suddenly, I could easily find out if a specific supplement worked with or against a specific medication, in the context of a specific auto-immune condition, and not have to sift thru 20 different SEO-bloated google links or wonder about hallucinations. I could just simply look at the cited reference material to gauge the informational trust level.
It was almost like having a Lyme specialist in house. At this time I still could not type or sit at a computer for more than a few minutes, so most of this interaction and coding was done via Whisper, another game-changing product from OpenAI. Earlier that year, I made a little python app that recorded my voice when I hit a keyboard shortcut. It then sent the audio as mp3 files to OpenAI's Whisper API which transcribed them with 99.9% accuracy (for comparison, Siri was like 15% accuracy).
I spent many hours talking to LymeGPT via Whisper. My goal was to research as many potential treatment ideas as I could, then take them to my doctor and ask his opinion. This significantly increased the scope and range of potential ideas that could be considered. Prior to this, my doctor would rarely propose or discuss new ideas. But this got the conversation going in productive directions, and my doctor was still the final authority on what I should do.
Perhaps it's coincidence, but it was around this time I started to see more rapid and sustained improvement. Within a few months I went from being 95% bedridden, to being able to walk around my block and do some chores around the house. A few months later I could swim in the ocean! My health continued to slowly improve from there. So, maybe... AI saved my life? Whether or not that's literally true, if used correctly, I am proof that AI will be a significant advantage for navigating these complex health conditions where expertise is super expensive or hard to find. I assume Lyme Disease is just one of many that fit that description.
AI has rapidly improved since I made LymeGPT, but this is still the ideal way to use AI. It works best as an AI + Human-expert-in-the-loop collaboration. I expect that won't change until we get all the way AGI. Its similar to Tesla's self driving - it can do most of the driving but you still need to supervise.
I've learned a lot since that first Langchain prototype, and the tech has progressed significantly. Custom GPT's that do RAG are trivial to make now, especially if you use OpenAI's custom GPT builder which launched a few months ago. AWS Bedrock also introduced a "Knowledge Base" feature which does RAG-as-a-Service. I was eager to try this out and compare its flexibility and performance to my Langchain setup, so I made a new modernized version of LymeGPT using AWS Bedrock and added a simple web frontend using Streamlit.
LymeGPT is live on Streamlit Cloud. The username and password are both "lyme". The stack I used is all free tier stuff (except the model)- AWS Bedrock, OpenSearch VectorStore Serverless, Claude3-Sonnet, AWS Lambda, and Streamlit Cloud.
The public repo for LymeGPT is at this github link. The README is detailed enough that anyone with AWS experience can clone the repo and quickly build a similar RAG app, as this is meant to be a template.
Project Takeaways
You'll notice a bit of a lag when first starting the chat. This is because I setup a Lambda to sit between my streamlit frontend and RAG/LLM. But I would not recommend to casually put this in production! I was very curious to experiment with this design to see its cost and performance. Having a lambda function sit in the middle provides the usual advantages, however its not a cost-effective design out of the box. Lambdas bill based on execution time. LLM's, and especially RAG, have high variance in response time. Many of the Lambdas in this app ran for 10-15 seconds, most of that time its just idle and waiting for the LLM to respond.
I would recommend removing the Lambda from the design, and instead have the streamlit app talk directly to the RAG and LLM. However, this design is fine for a quick proof of concept and to get a feel for the different services involved, and the pros and cons compared to other services.
My favorite feature of RAG in general is how the chatbot UI cites the source text chunks used in generating the responses, which is a nice feature to confirm reliability. Also another benefit of using AWS is all the knowledge base data is stored in S3, so it can be easily updated and synced.
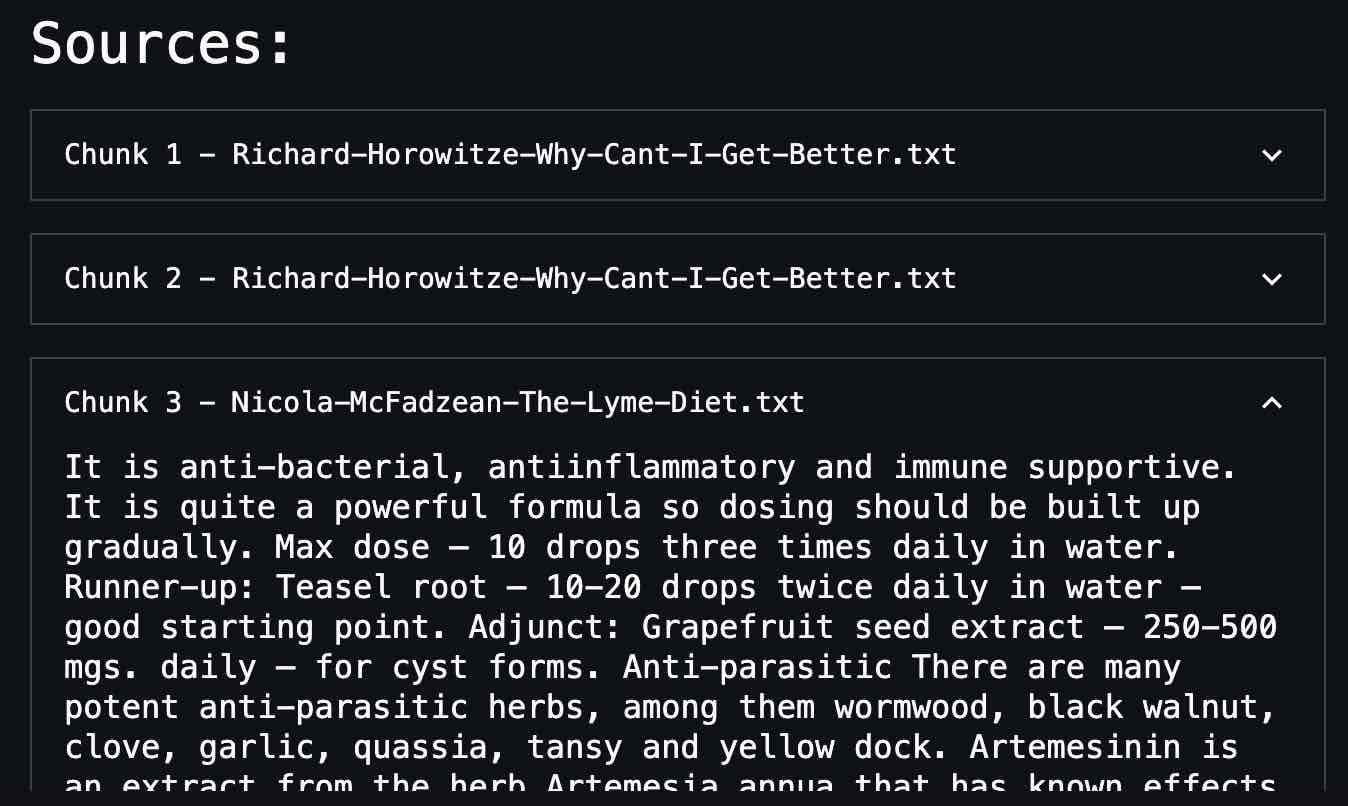
I hope this project inspires others to explore the possibilities of RAG applications in their own lives, especially for complex topics like health challenges. For most personal use cases, I would recommend using services like ChatGPT's custom GPT's. But if privacy is a concern, or you need more functionality feel free to check out the LymeGPT GitHub repository for more details.
Disclaimer: LymeGPT is for informational purposes only and should not be considered medical advice. Always consult with a qualified healthcare professional for medical diagnosis and treatment.